About 8 years ago, I posted about large and cheap storage/backup solutions. About that time, I subscribed to my favorite pick in this list. And it seemed pretty great. Lots of space for manual storage and “unlimited” space for automatic backups (NB: “unlimited” for automatic backups means it’s actually quite limited, by the storage size on your backed-up computers + the limited amount of folders you choose to back up). All good, so far.
It all began with a payment processing issue…
Fast forwarding to 8 years later. I’m a bit late for my renewal, as usual. Well, not late-late, but late “just a few days before the deadline”. Because I use single-use debit cards (“e-cards”), and the core concept of those is “you create it, you use it immediately”.
And for the first time in 8 years, it’s rejected. Not “not enough funds” rejected, not “bank declined for some reason” rejected, just “we failed to process your payment try again” rejected. I tried lots of things: other e-cards, even physical cards, completing my billing address, which had been partial from the beginning, without it being an issue ever, etc. Nothing worked.
Contacted support and waited.
… but support was unresponsive
It was Friday, more or less in the middle of the day… You guessed it, they didn’t reply before the weekend. Yikes.
But as we’ll see later on, it turned out to be a blessing in disguise.
So I waited, during the weekend.
But as we’ll see later on, that was a bit stupid.
Monday morning now. Last day paid for in my current subscription state. Getting a bit nervous there…
Midday. Getting a bad feeling about this. If you have a customer writing to you because they want to pay you, you wouldn’t leave them hanging, would you? I start thinking about holidays for some reason, so I look a bit online, and…
Spring Bank Holiday
Bloody Hell. Hurray for a UK company 😡
So I started recovering my backup…
Sounds like a good time to start panicking. I assume they have a grace period, but I decide I’ll try to download as much of my backup as I can. A quick calculation shows I won’t have time to download everything before the end of the day (told you waiting had been a bit stupid). Great, now I have to pick. Good thing I mostly have large files: downloading the first few will give me a lot of time to think about the next ones. I start downloading.
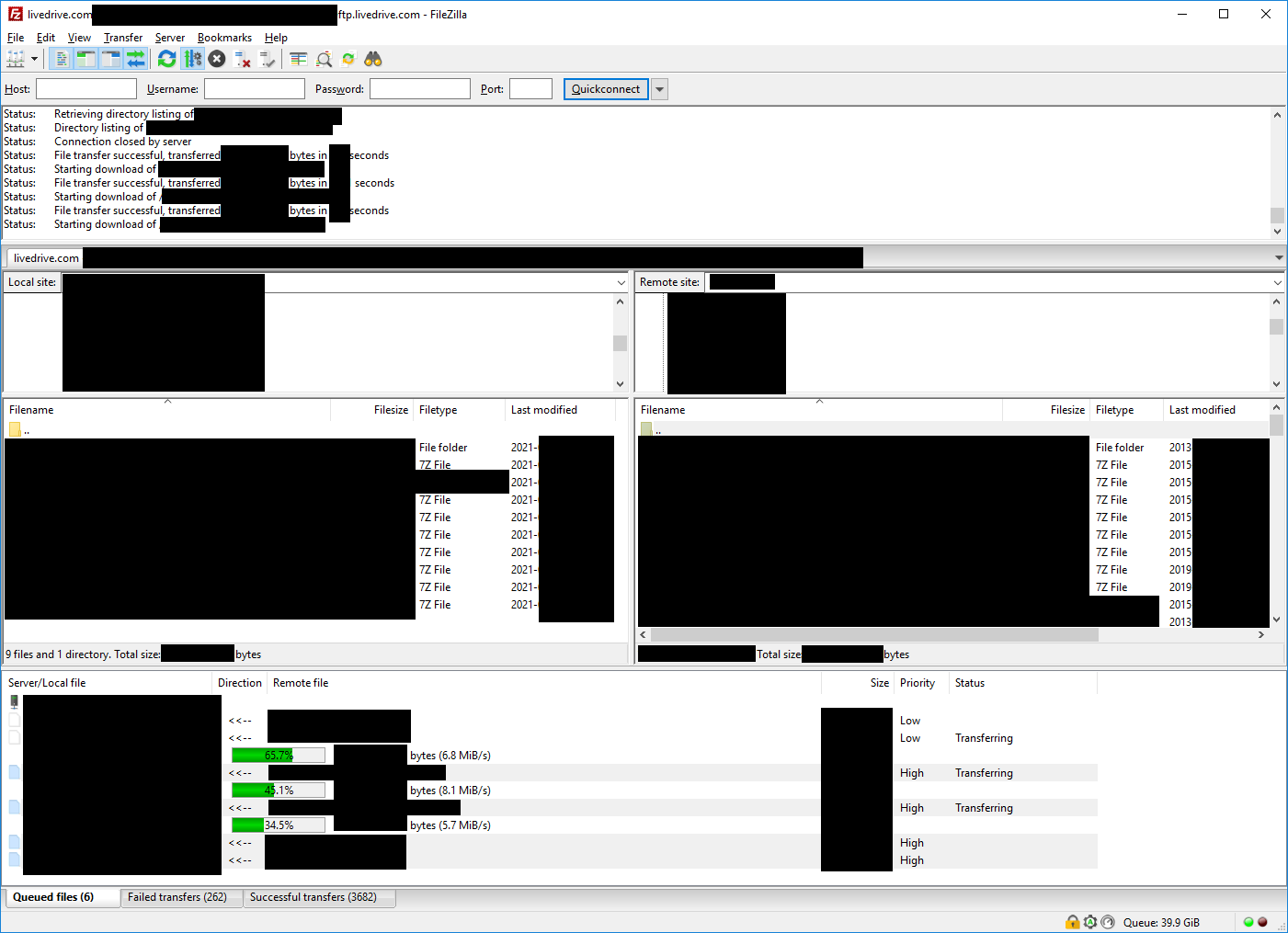
And this is where things go incredibly south. Let’s say nothing about SFTP being so unusably slow that I had to use FTP (“Welcome to 2001… wait, aren’t we in 2021?”), and let a picture be worth a thousand words. Or a few thousand files:
… only to find it was largely unrecoverable
Did you see it? No? Look at the bottom. Still no? Bottom-left. That’s right: for 3944 total files, 262 failed! That’s over 6.6% (almost 6.66%, the number of the Beast 👀). And I retried a bunch of them: it didn’t change a thing. A lost file was a lost file. For. Fuck. Sake.
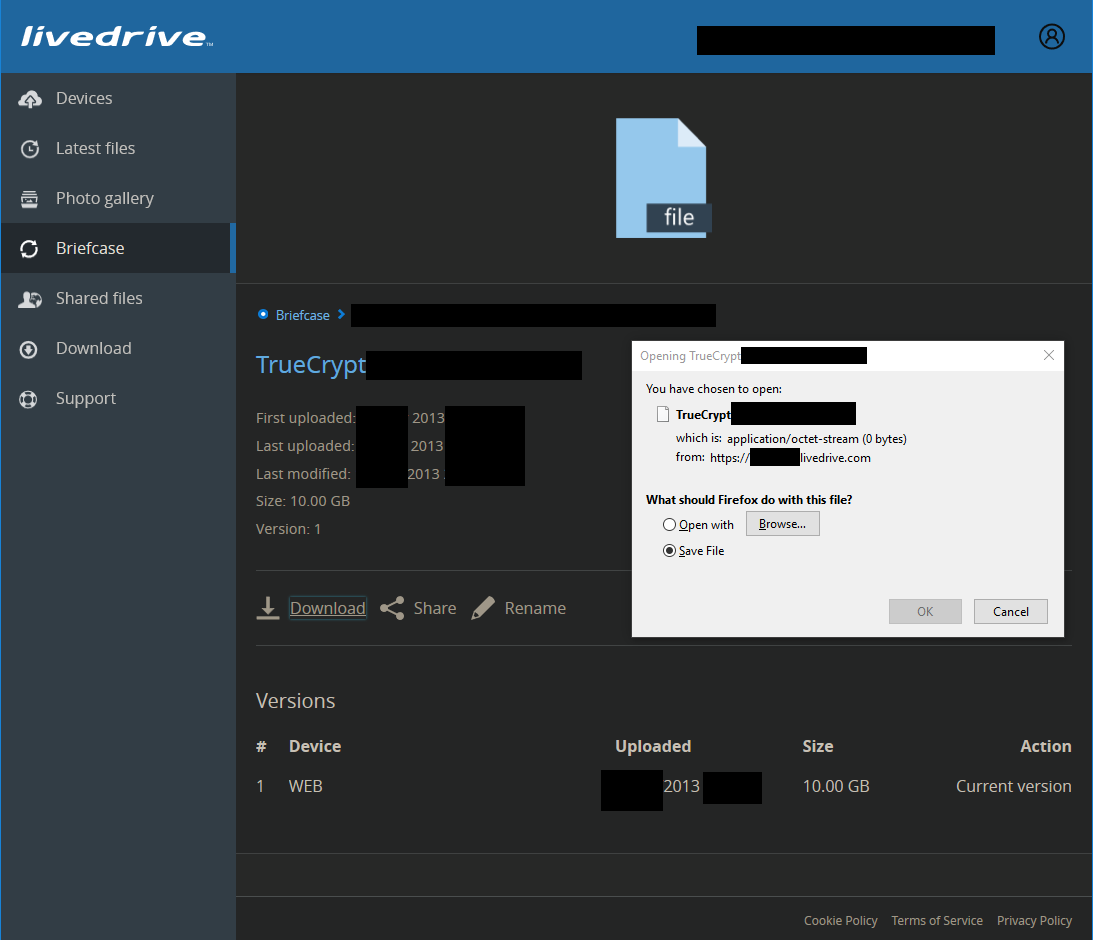
I also gave a try to downloading from the web interface. Admire how a 10 GB file turns into a 0-byte file, without the slightest error message. “Everything normal, SNAFU”. Splendid:
Fun fact: file size didn’t seem to matter in how likely it was for a file to be lost. If random clusters would get lost, and as a result would doom the large file they were a part of, I would expect to lose almost all my huge files, and not nearly as many small files. But no, I lost many “small” files (a few MB), and not that many “huge” files (more than 5 GB). I seriously wonder how the hell you lose random files rather than random clusters… My best guess is 1) no data replication at all and 2) each file is placed on a single, random hard drive (independently from the time of upload, as files I had uploaded together didn’t necessarily had the same conservation status).
So I left
From that moment on, obviously I was fully decided not to renew my subscription. So I kept downloading even faster. I actually managed to get back most of my data, as my account wasn’t cut off at midnight, but kind of late in the following afternoon. Had I let it run for the night (silly me… :/), I would probably have gotten back everything. That is, everything that hadn’t been lost.
So, as I said earlier, that payment failure was a blessing in disguise, since it made me realize I was paying for a backup that pretty much had no value. 168€/year for 5TB for storage (+ automated backups, this I haven’t replaced yet).
Let’s talk a bit about what happened afterwards. After the account was suspended, I regularly received e-mail reminders, more precisely: within 1-2 hours after suspension, then at day 5, 10, 20 and 1 month. That last e-mail mentioned that it was a final reminder and that the account would be erased after 30 days. I logged into my account just 4 weeks after receiving that e-mail, and it was indeed still there (suspended, with just a payment form to reactivate it).
All in all, they give the impression of an honest company that does its best to make sure data don’t get wiped by accident (although 2 months isn’t that long, I guess they can’t keep the data forever either, it does have a cost). Only their best is far, far below reasonable expectations, as far as data integrity goes.
A new dawn
Moving on, I’m currently giving a spin to Backblaze, which I had been very hesitant about for a while, notably because of their unusual transfer protocol: they use their own. Cyberduck can handle it, but that’s pretty much it as far as open source clients go, I believe.
Still $0.005/GB/month, so for the price of Livedrive, in pure storage, I get 2.8TB. With lots of redundancy this time. Note that they bill for lots of little things: if you know AWS S3, Azure or other “cloud” providers, it’s a bit the same concept, every single action / API call is billable. In Backblaze’s case, there’s a free daily allowance that should help you avoid most of these little extra costs, if you spread your activity regularly rather than do tons of things one day, then nothing for ages. And there’s another billable thing, which this time is a big one: downloads. $0.01/GB (1GB free per day). That can pile up pretty quickly, and if I take the example of my emergency escape from Livedrive, downloading 2TB is therefore $20. Which is both “not nothing”, but also “not that much”. Better than losing 5%+ of my files, anyway.
Another nice thing with Backblaze, is that it will give me an incentive to minimize my storage, aka to stop freaking hoarding ^^. While Livedrive’s pricing was on the contrary an incentive to hover around 5TB…


Recent Comments